歸人顧名思義就是將一個人多筆的資料整合,每人只留下1筆。
通常取得的資料都是原始資料,並未經過整理。例如手上有疑份顧客購物紀錄,裡面有每個顧客在這1年內的每筆消費紀錄,這是一份以每次消費紀錄為1筆的紀錄形式,所以一個人可以有多筆的消費紀錄。當我們想要知道這些消費紀錄源自於多少顧客的購買時,這時候就需要用到歸人的概念,將資料轉換為每一個人只有1筆資料的紀錄形式(如下圖所示)。

以SAS進行資料歸人
歸人留1筆消費紀錄
proc sort data=cost;by ID time;run; /*在規筆前依照ID跟消費日期做排序*/
data cost_1;set cost;by
ID;
if first.id;run; /*保留第一筆資料*/
之前已經有針對proc sort的排序語法進行說明,有需要可參考這篇文章,SAS排序的設定值為升冪,也就是說每個人都會從最早那次的紀錄開始往後排序,所以用first.id就可以留下每個人最早那次的消費紀錄。

這邊也可以用排除重複的概念保留1筆資料
proc sort data=cost
out=cost_2 nodupkey;
BY ID;
run;
利用nodupkey,將ID重複的資料刪除,僅保留每個ID第一次出現的該筆紀錄。
歸人累計所有消費金額
proc sort data=cost;by ID time;run;
data cost_1;set cost;by
ID;
if first.id then count=0;/*每個人第一筆資料都令count=0*/
count+NT;/*同ID累計NT數值*/
if last.id;run;
除了要歸人以外,還要累計每個仁所有的消費金額,所以這邊就會創建一個count欄位,每一個人的第一筆ID令count=0,在同樣ID時累加NT的數值,最後每個人保留最後一筆ID,也就是最後累計的總額。
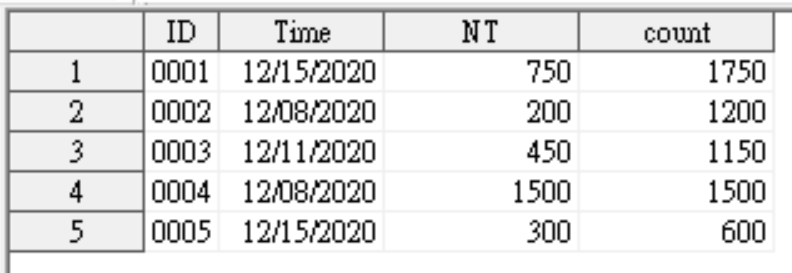
以Python進行資料歸人
歸人留1筆消費紀錄
cost.sort_values(["ID","Time"], inplace=True)
drop_duplicates指令預設保留第一筆,雖然不需排序即可執行,但如果希望保留正確的資料,還是務必排序。

歸人累計所有消費金額
cost.sort_values(["ID","Time"], inplace=True)
cost["count"]=cost["NT"].groupby(cost["ID"]).cumsum()
cost_1= cost.drop_duplicates("ID",keep="last") #設定保留第一筆,用keep="last"可保留最後1筆pandas用groupby函數來定義那些資料屬於同一群,再用cumsum函數來累計同一群人NT欄位的數值。最後drop_duplicates來歸人。

這跟上一篇介紹的邏輯判斷一樣,都很常運用於資料處理的過程,所以熟悉這些語法後,在資料處理上會相當得心應手。
留言
張貼留言